Structured concurrency in Swift explained
Published on: March 17, 2023Updated on: July 4, 2025
Swift's async await syntax heavily relies on a concept called Structured Concurrency. Structured concurrency describes the relationship between tasks that perform concurrent work. Specifically, it defines the relationship between parent and child tasks in Swift. Structured Concurrency finds its roots in the fork join model which is a model that stems from the sixties.
In this post, I will explain what structured concurrency means, and how it plays an important role in Swift Concurrency.
Note that this post is not an introduction to using async and await in Swift. IIf you're interested in learning more about async await in Swift, I highly recommend that you take a look at the Swift Concurrency category. These posts all help you learn specific bits and pieces of modern Concurrency in Swift. For example, how you can use task groups, actors, async sequences, and more.
If you're looking for a full introduction to async await in Swift, I recommend you check out my book. In my book I go in depth on all the important parts of Swift Concurrency that you need to know in order to make the most out of modern concurrency features in Swift.
Anyway, back to structured concurrency. We’ll start by looking at the concept from a high level before looking at a few examples of Swift code that illustrates the concepts of structured concurrency nicely.
Understanding the concept of structured concurrency
The concepts behind Swift’s structured concurrency are neither new nor unique. Sure, Swift implements some things in its own unique way but the core idea of structured concurrency can be dated back all the way to the sixties in the form of the fork join model.
The fork join model describes how a program that performs multiple pieces of work in parallel (fork) will wait for all work to complete, receiving the results from each piece of work (join) before continuing to the next piece of work.
We can visualize the fork join model as follows:
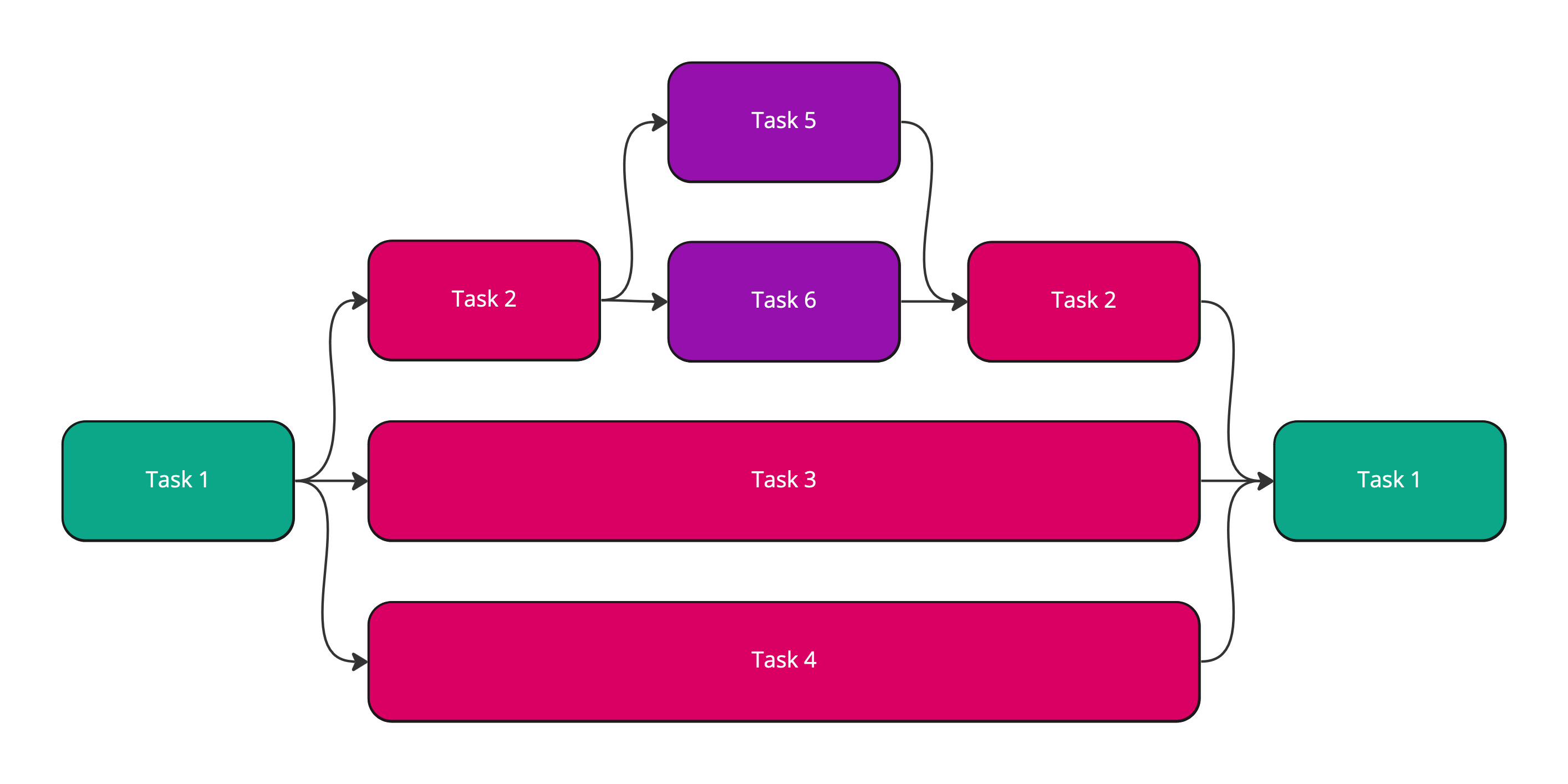
In the graphic above you can see that the first task kicks off three other tasks. One of these tasks kicks off some sub-tasks of its own. The original task cannot complete until it has received the results from each of the tasks it spawned. The same applies to the sub-task that kicks of its own sub-tasks.
You can see that the two purple colored tasks must complete before the task labelled as Task 2 can complete. Once Task 2 is completed we can proceed with allowing Task 1 to complete.
Swift Concurrency is heavily based on this model but it expands on some of the details a little bit.
For example, the fork join model does not formally describe a way for a program to ensure correct execution at runtime while Swift does provide these kinds of runtime checks. Swift also provides a detailed description of how error propagation works in a structured concurrency setting.
When any of the child tasks spawned in structured concurrency fails with an error, the parent task can decide to handle that error and allow other child tasks to resume and complete. Alternatively, a parent task can decide to cancel all child tasks and make the error the joined result of all child tasks.
In either scenario, the parent task cannot complete while the child tasks are still running. If there’s one thing you should understand about structured concurrency that would be it. Structured concurrency’s main focus is describing how parent and child tasks relate to each other, and how a parent task can not complete when one or more of its child tasks are still running.
So what does that translate to when we explore structured concurrency in Swift specifically? Let’s find out!
Structured concurrency in action
In its simplest and most basic form structured concurrency in Swift means that you start a task, perform some work, await some async calls, and eventually your task completes. This could look as follows:
func parseFiles() async throws -> [ParsedFile] {
var parsedFiles = [ParsedFile]()
for file in list {
let result = try await parseFile(file)
parsedFiles.append(result)
}
return parsedFiles
}The execution for our function above is linear. We iterate over a list of files, we await an asynchronous function for each file in the list, and we return a list of parsed files. We only work on a single file at a time and at no point does this function fork out into any parallel work.
We know that at some point our parseFiles() function was called as part of a Task. This task could be part of a group of child tasks, it could be task that was created with SwiftUI’s task view modifier, it could be a task that was created with Task.detached. We really don’t know. And it also doesn’t really matter because regardless of the task that this function was called from, this function will always run the same.
However, we’re not seeing the power of structured concurrency in this example. The real power of structured concurrency comes when we introduce child tasks into the mix. Two ways to create child tasks in Swift Concurrency are to leverage async let or TaskGroup. I have detailed posts on both of these topics so I won’t go in depth on them in this post:
- Running tasks in parallel with Swift Concurrency’s task groups
- Running tasks concurrently with Swift Concurrency’s async let
Since async let has the most lightweight syntax of the two, I will illustrate structured concurrency using async let rather than through a TaskGroup. Note that both techniques spawn child tasks which means that they both adhere to the rules from structured concurrency even though there are differences in the problems that TaskGroup and async let solve.
Imagine that we’d like to implement some code that follows the fork join model graphic that I showed you earlier:
We could write a function that spawns three child tasks, and then one of the three child tasks spawns two child tasks of its own.
The following code shows what that looks like with async let. Note that I’ve omitted various details like the implementation of certain classes or functions. The details of these are not relevant for this example. The key information you’re looking for is how we can kick off lots of work while Swift makes sure that all work we kick off is completed before we return from our buildDataStructure function.
func buildDataStructure() async -> DataStructure {
async let configurationsTask = loadConfigurations()
async let restoredStateTask = loadState()
async let userDataTask = fetchUserData()
let config = await configurationsTask
let state = await restoredStateTask
let data = await userDataTask
return DataStructure(config, state, data)
}
func loadConfigurations() async -> [Configuration] {
async let localConfigTask = configProvider.local()
async let remoteConfigTask = configProvider.remote()
let (localConfig, remoteConfig) = await (localConfigTask, remoteConfigTask)
return localConfig.apply(remoteConfig)
}The code above implements the same structure that is outlined in the fork join sample image.
We do everything exactly as we’re supposed to. All tasks we create with async let are awaited before the function that we created them in returns. But what happens when we forget to await one of these tasks?
For example, what if we write the following code?
func buildDataStructure() async -> DataStructure? {
async let configurationsTask = loadConfigurations()
async let restoredStateTask = loadState()
async let userDataTask = fetchUserData()
return nil
}The code above will compile perfectly fine. You would see a warning about some unused properties but all in all your code will compile and it will run just fine.
The three async let properties that are created each represent a child task and as you know each child task must complete before their parent task can complete. In this case, that guarantee will be made by the buildDataStructure function. As soon as that function returns it will cancel any running child tasks. Each child task must then wrap up what they’re doing and honor this request for cancellation. Swift will never abruptly stop executing a task due to cancellation; cancellation is always cooperative in Swift.
Because cancellation is cooperative Swift will not only cancel the running child tasks, it will also implicitly await them. In other words, because we don’t know whether cancellation will be honored immediately, the parent task will implicitly await the child tasks to make sure that all child tasks are completed before resuming.
How unstructured and detached tasks relate to structured concurrency
In addition to structured concurrency, we have unstructured concurrency. Unstructured concurrency allows us to create tasks that are created as stand alone islands of concurrency. They do not have a parent task, and they can outlive the task that they were created from. Hence the term unstructured. When you create an unstructured task, certain attributes from the source task are carried over. For example, if your source task is main actor bound then any unstructured tasks created from that task will also be main actor bound.
Similarly if you create an unstructured task from a task that has task local values, these values are inherited by your unstructured task. The same is true for task priorities.
However, because an unstructured task can outlive the task that it got created from, an unstructured task will not be cancelled or completed when the source task is cancelled or completed.
An unstructured task is created using the default Task initializer:
func spawnUnstructured() async {
Task {
print("this is printed from an unstructured task")
}
}We can also create detached tasks. These tasks are both unstructured as well as completely detached from the context that they were created from. They do not inherit any task local values, they do not inherit actor, and they do not inherit priority.
I cover detached and unstructured tasks more in depth right here.
In Summary
In this post, you learned what structured concurrency means in Swift, and what its primary rule is. You saw that structured concurrency is based on a model called the fork join model which describes how tasks can spawn other tasks that run in parallel and how all spawned tasks must complete before the parent task can complete.
This model is really powerful and it provides a lot of clarity and safety around the way Swift Concurrency deals with parent / child tasks that are created with either a task group or an async let.
We explored structured concurrency in action by writing a function that leveraged various async let properties to spawn child tasks, and you learned that Swift Concurrency provides runtime guarantees around structured concurrency by implicitly awaiting any running child tasks before our parent task can complete. In our example this meant awaiting all async let properties before returning from our function.
You also learned that we can create unstructured or detached tasks with Task.init and Task.detached. I explained that both unstructured and detached tasks are never child tasks of the context that they were created in, but that unstructured tasks do inherit some context from the context they were created in.
All in all the most important thing to understand about structured concurrency is that it provide clear and rigid rules around the relationship between parent and child tasks. In particular it describes how all child tasks must complete before a parent task can complete.
